


Bringing AI models and inferencing to the IoT
The implementation of AI is shifting away from the Cloud to the Edge. Bandwidth and latency are key issues when conducting inferencing in the Cloud for Edge applications, making inference at the source critical for many IoT applications. As a result, the demand for more computing power is also rising at the Edge.
However, the Edge is a highly fragmented space, comprising markets such as industrial, smartphones, consumer, and wearables. Contextual LLMs that support audio, voice, text, and video are placing increasing demands on IoT compute, from hundreds of GOPS to tens of TOPS and beyond. Addressing this, Synaptics is offering the Astra SL2600 Series of multimodal Edge AI processors, which currently comprises the 2610 line of Edge AI processors, and is designed to deliver exceptional power and performance, enabling a new generation of cost-effective intelligent devices that make the cognitive Internet of Things (IoT) possible.
Nebu Philips, Senior Director, Technical Product Marketing at Synaptics, commented, “The key to addressing the entry of AI into the fragmented Edge market is to provide the right class of silicon and software to be able to address the processing requirements of the entire edge.”
Edge AI in a rapidly changing market
The Edge market is currently experiencing rapid changes in devices and capabilities. Further, scaling Edge applications is not easy. The key issue is that AI software, models and frameworks are changing rapidly, driven by a multitude of startups and cloud providers. As the existing silicon class is unable to keep pace with the rate of innovation on the software side, silicon vendors face a challenging design environment, especially for multi-million USD projects that require a long lifetime. The fast-paced innovation across the AI software ecosystem — including models, algorithms, frameworks, compilers, and runtimes — is challenging design methods and product development.
In terms of software, large language models (LLMs) are relatively stable, as hyperscalers like Meta and Google Research have established model frameworks. These include LiteRT, TensorFlow, ONNX, PyTorch, and the new Google Research model format, JAX. Designers are getting familiar with these models. Running on the Cloud, these models only need to consider Nvidia or AMD GPUs. However, at the Edge, silicon is provided by many vendors, each with different compilers closely tied to their own products. Once committed to a specific compiler, it becomes difficult and expensive to change, potentially leading to vendor lock-in.
Nebu Philips comments, “The use of proprietary Edge AI compilers and custom approaches to integrating models into application workflows is creating walled-garden experiences and lock-ins for OEMs.”
AI architecture, open-source and partnerships
Synaptics aims to scale in the AI inferencing Edge silicon market through three key strategies. First, the company is addressing scalable, secure silicon architectures that enable SoCs to adapt to evolving AI model formats and operators, minimising the risk of obsolescence as standards change or new operators are added. Second, Synaptics is promoting open-source, standards-based AI software, particularly in areas such as model combiners, to prevent fragmentation and foster industry-wide innovation. Third, they seek to build partnerships with influential ecosystem players to establish best practices, drive industry standards, and support robust application development for general AI hardware.
Earlier this year, Synaptics entered into a multi-generational silicon partnership with Google Research on the Edge TPU project. The TPU (Tensor Processing Unit) is an ASIC developed by Google Research to accelerate machine learning and neural network computation. Years ago, Google Research started the Edge TPU project as a silicon play. Originally, TPUs were designed for the Cloud, but Google then brought that TPU architecture down to the Edge. Google Research has since de-emphasised the silicon manufacturing angle and instead created open-source IP that anyone can integrate into silicon and bring to market.
Nebu Philips adds, “Google Research is focused on building an ecosystem with a clean development pipeline connecting edge devices and the Cloud. Currently, monetisation strategies are based on the Cloud. The aim is to level the playing field to enable data extraction from the Edge to the Cloud. For Synaptics, the partnership advances state-of-the-art model deployment and offers competitive advantages by enabling early access to new platforms and gaining market share as a pioneering partner.”
When designing Edge SoCs for AI workloads, standard ARM-based compute alone is insufficient to address evolving requirements. A key addition to a new architecture that builds on standard ARM-based computing must integrate specialised I/O pipelines that are capable of handling vision, audio, and environmental inputs. The new architecture ensures data can flow efficiently into inference engines. In addition, security and confidentiality for multi-tenant workloads are essential considerations.
In this new architecture, one MPU can be used to accelerate transformers, which is essentially all the state-of-the-art models. Closely tied to it are two other elements. One is the use of localised scalar computing to handle new instructions or collections of instructions that are not yet defined, as well as operations that are not yet available. Secondly, a shared, low-latency, high-performance SRAM connects these two computer domains—enabling flexible scaling and ensuring compatibility with new AI workloads as models evolve.
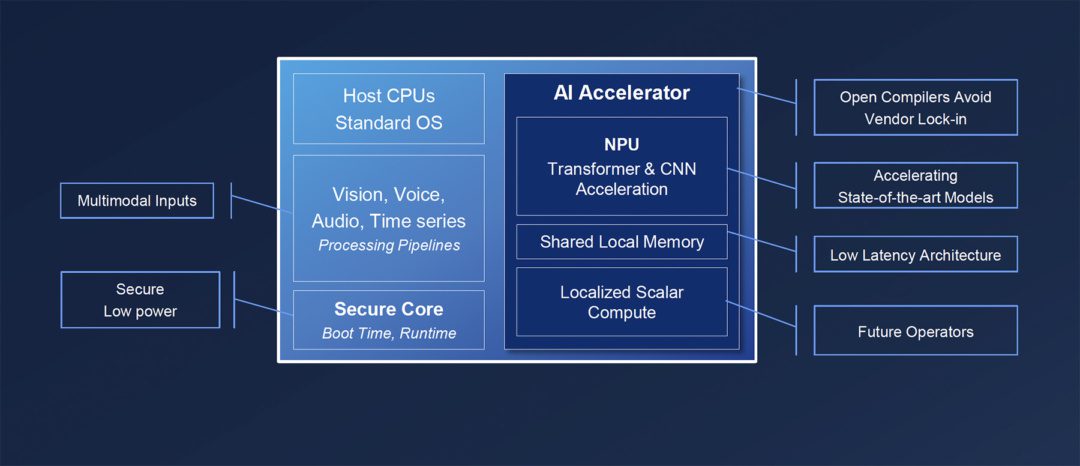
Figure 1: New architecture for scalable secure processors for Edge AI.
Inside the Astra SL2610 line of Edge AI processors
The new Astra SL2610 line of Edge AI processors encompasses five pin-to-pin-compatible families — SL2611, SL2613, SL2615, SL2617, and SL2619 — built for a wide range of applications, from battery-powered and passively cooled devices to high-performance industrial vision systems. These processors deliver high power efficiency and seamless integration with Synaptics Veros Connectivity across Wi-Fi 6/6E/7, BT/BLE, Thread, and UWB, providing a unified developer experience that accelerates time-to-market.
“With the Astra SL2610 line of Edge AI processors, Synaptics is redefining what’s possible for Edge AI. Through industry-leading power efficiency and breakthrough multimodal AI acceleration, these processors deliver the architectural foundation for customers to design scalable, next-generation IoT,” said Vikram Gupta, Senior Vice President and General Manager, Edge AI IoT Processors, Synaptics.
Synaptics also offers the SL1600 Series AI-native Linux and Android AI processors, as well as the SR100 high-performance context-aware AI MCUs, both in production. The SR 200 Series is in development.
The highest-end products in the SL2610 line of Edge AI processors, the SL2619 family features dual 2-GHz Arm Cortex A55 cores and a low-power Arm Cortex-M52 MC-based subsystem for system management, power management, and secure boot. It includes a dedicated crypto accelerator and supports multimodal video and audio input pipelines.
The standout feature is the Torq NPU subsystem, which comprises a Synaptics-designed, scalable T1 NPU for low-latency, high-throughput hardware acceleration of transformer and convolutional neural network (CNN) models, combined with the Google open-source Coral NPU, a RISC-V-based, low-power, highly programmable engine. The Coral NPU, tightly integrated with the Torq AI subsystem, is designed to handle new and unsupported instructions. Anything the T1 cannot process can be ported to the Coral NPU. This setup enables a tiered processing system that is intelligently managed, providing a flexible programming model between the fully accelerated compute engines, the RISC-V core and the dual-core Arm host processor, enabling optimal resource utilisation. The implementation of the Google Coral NPU ML RISC-V accelerator is an industry first.
The software is the second half of the Torq platform, offering a compiler, runtime, build framework, and other tools to leverage the NPU. It enables developers to create multimodal AI applications for vision, audio, and voice that run seamlessly on the NPU.
In contrast with other AI compilers, which are typically proprietary and closed source, Torq features an open-source compiler, developed in partnership with Google Research. By making the compiler and toolchain open source, Synaptics and Google Research aim to create a more accessible ecosystem for developers.
The SL2619 also delivers edge security with hardware anchor, threat detection and application cryptography.
Solving the compiler problem
A trend over the last few years has been for silicon vendors to acquire tooling companies and tightly integrate the tools into their silicon portfolios, enabling OEMs to develop products. However, this locks OEMs into a vendor-specific proprietary tooling experience, reducing choice. To address this, the MLIR (Multi-Level Intermediate Representation) project provides a fully open-source, modular compiler infrastructure that supports multiple abstraction levels. Originally developed primarily by Google Research and maintained as part of the LLVM project, MLIR enables seamless ingestion of diverse model formats (PyTorch, ONNX, JAX) and compilation into binaries deployable across different AI engine subsystems in silicon. Furthermore, it is entirely open source from start to finish.
Torq uses IREE (Intermediate Representation Execution Environment), which is an end-to-end compiler and runtime framework built on top of the MLIR compiler infrastructure. It uses the modular and extensible intermediate representations of MLIR to compile and optimise machine learning models for diverse hardware targets, including CPUs, GPUs, and accelerators, enabling seamless model deployment across platforms.
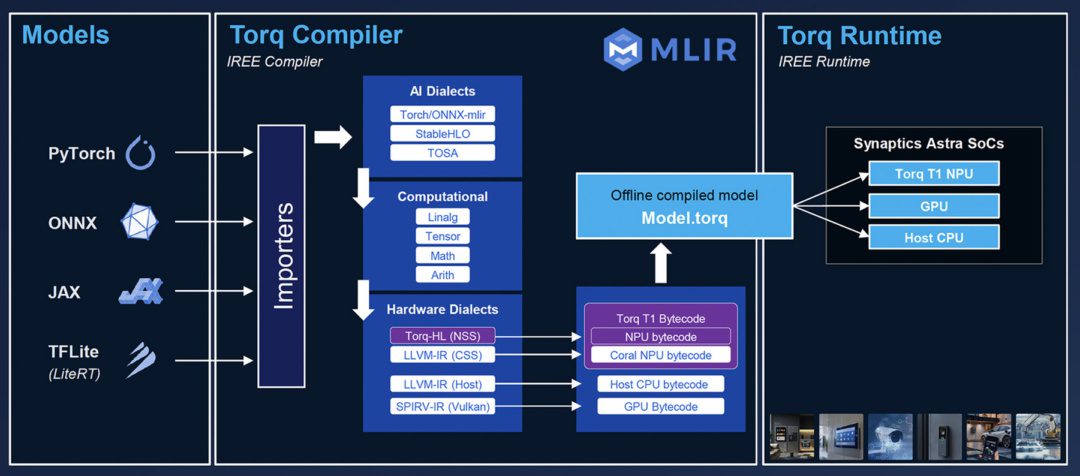
The Torq end-to-end compiler and runtime framework.
Nebu Philips comments, “This levels the playing field as developers are not beholden to proprietary compilers and tooling from a large silicon vendor anymore. A combination of a future-ready AI architecture with open source tooling is going to be very disruptive, in a positive way, in the IoT space.”
Synaptics brings all its open-source Edge AI software and tools together at developer.synaptics.com. This interactive resource enables users to start with a collection of models, optimise them, and then run them on readily available development kits. The software and tools allow users to complete an evaluation right at the desktop and then optimise it further.
Looking ahead
The 2610 line of Edge AI processors within the 2600 series is the entry-level offering in the premium range. It is very power-efficient and can run on battery-powered systems or be used in energy-harvesting designs. Towards the end of next year, Synaptics will have a mid-range set of families.
The 2010 line Edge AI processors implements a 1-TOP implementation of the CPU. However, the efficiency is much higher due to the architecture, even compared to 4-TOPS or 8-TOPS devices using existing architectures. Key to the low-power, high-efficiency design is the use of the RISC-V Coral NPU, a sub-ten-milliwatt implementation. The 2010 line is just the first generation, which is built to accelerate scalar instructions today. The second generation will accelerate vector instructions, while the third generation will feature matrix instructions.
Quantum resistance and cryptographic algorithms are also on the roadmap, but they are not ready for implementation in silicon because standards are still evolving. However, the Google Research team is also looking at CHERI (Capability Hardware Enhanced RISC Instructions), a research project led principally by the University of Cambridge in collaboration with SRI International. CHERI enhances ISA architectures such as RISC-V and Arm with capability-based security features, primarily providing fine-grained memory protection. Implementing this IP is also on the roadmap.
Bringing AI models to the Edge
Bringing AI models and inferencing to the IoT represents a transformative shift from cloud-centric to edge-centric computing, addressing critical challenges of latency, bandwidth, and data privacy. The ability to process data locally with Edge AI enables real-time decision-making, enhances security by minimising data transmission, and reduces reliance on the Cloud. However, the fragmented nature of the IoT market demands adaptable silicon and open software ecosystems to accommodate rapidly evolving AI models and diverse application needs. The Astra SL2600 Series, with scalable architectures, efficient power use, and flexible NPUs, demonstrates how next-generation hardware can empower multimodal AI workloads at the Edge. Partnerships, such as the multi-generational Synaptics-Google Research collaboration and open-source toolchains like MLIR and IREE, drive innovation and mitigate vendor lock-in. Looking ahead, ongoing advancements in processor design, security features like CHERI, and cryptographic enhancements will further unlock IoT’s potential, enabling intelligent, secure, and efficient edge AI applications that redefine the future of connected devices.
Register interest in the Astra Machina SL2610 dev kit here: https://synacsm.atlassian.net/servicedesk/customer/portal/543/group/597/create/7992
Related links
www.synaptics.com
https://mlir.llvm.org
https://iree.dev
https://llvm.org
https://github.com/llvm/llvm-project
https://research.google
https://developers.google.com/coral
https://github.com/google-coral/coralnpu
https://cheri-alliance.org
https://onnx.ai
https://github.com/onnx/onnx
https://pytorch.org
https://github.com/pytorch/pytorch
https://ai.google.dev/edge/litert
https://github.com/google-ai-edge/LiteRT
https://huggingface.co/litert-community
https://www.tensorflow.org
https://github.com/tensorflow/tensorflow
https://docs.jax.dev/en/latest
https://github.com/jax-ml/jax
https://github.com/synaptics-torq
 If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :
If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :




