

Flex Logix tips move into NN processing
However, although the company has already completed some of the compiler work the technology is still in development and is not expected to tape out or have IP availability until the second half of 2019.
The company has exploited the similarities between the sea-of-lookup-tables of FPGA fabric and the sea-of-MACs fabric that can support artificial neural networks for inferencing and come up with its NMAX architecture.
FPGA-style interconnect structure is good for moving data efficiently, Flex Logix CEO Geoff Tate, told eeNews Europe. The architecture is being optimized for inferencing at the edge where such features as low batch size and low latency are valued. “Things like Google’s TPU [tensor processing unit] batch up 100s of pictures for the efficient use of architecture but it is inevitably low latency,” Tate said.
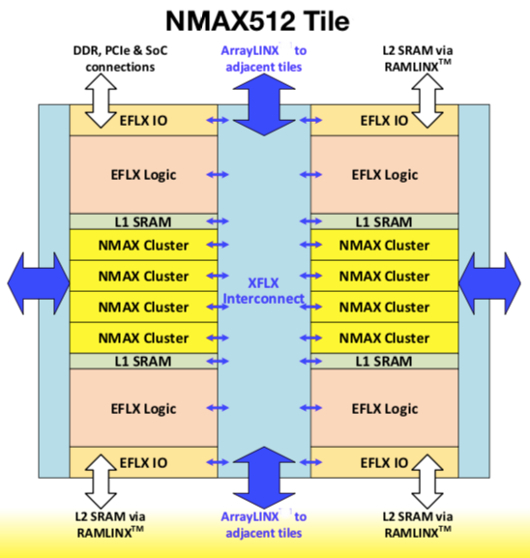
NMAX512 tile with standardized periphery to allow tiling and xFLX universal interconnect. Source: Flex Logix.
To address low latency applications in areas such as sensor fusion and automotive vision processing Flex Logix has developed the NMAX512 tile of 512 multiply accumulate (MAC) units with local SRAM. Implemented in a 16nm CMOS process the tile has peak performance of about 1TOPS with a 1GHz clock frequency and occupying an area of about 2 square millimeters.
In neural inferencing, the computation is primarily trillions of operations (multiplies and accumulates, typically using 8-bit integer inputs and weights, and sometimes 16-bit integer, and this is what Flex Logix has chosen to support with interconnects that allow reconfigurable connections between SRAM input banks, MAC clusters, and activation to SRAM output banks at each stage.
Next: Meaningful arrays
NMAX tiles can be arrayed with varying amounts of SRAM to reach up to and beyond 100TOPS peak performance. The typical MAC efficiency of utilization is 50 to 90 percent, said Tate. The variable L2 and L3 memory means that ResNET, which doesn’t need much memory, and Yolo, which needs more memory can be supported optimally without storage of intermediate results.

Estimated performance of NMAX arrays and corresponding MAC utilization. Source: Flex Logix.
“While performance is key in inferencing, what sets NMAX apart is how it handles this data movement while using a fraction of the DRAM bandwidth that other inferencing solutions require. This dramatically cuts the power and cost of these solutions, which is something customers in edge applications require for volume deployment,” Tate said in a statement.
NMAX is a general purpose in that it can run most types of NN including recursive NNs and convolutional NNs and can run multiple NNs at a time. NMAX is programmed using Caffe or Tensorflow and NMAX compiler unrolls the NN automatically onto the NMAX hardware. Control logic and data operators are mapped to local reconfigurable logic.
Related links and articles:
News articles:
Eta adds spiking neural network support to MCU
Microsoft, Alexa, Bosch join Intel by investing in Syntiant
NovuMind benchmarks tensor processor
Is that Graphcore’s Colossus IPU in package?
Kneron launches improved line of NPUs
Gyrfalcon ships AI chip to Samsung, Fujitsu, LG
Machine learning chip startup raises $9 million
 If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :
If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :


