

Convolutional Neural Network on FPGA beats all efficiency benchmarks
The Omnitek Deep Learning Processing Unit (DPU) available now as a CNN will soon also be available as a Recurrent Neural Network (RNN) and a Multi-Layer Perceptions (MLP). In its highest performance implementation, the DPU features 12 CNN engines capable of churning out 20 TeraOps/s at better than 60% efficiency.
Discussing the merits of FPGAs for deep learning applications, Omnitek’s CEO Roger Fawcett emphasized that while ASICs or fixed architectures are rapidly becoming obsolete in the fast evolving world of artificial intelligence, FPGAs provide the only platform to be rewired from one machine learning architecture to the next to achieve optimum efficiency at different tasks. A new bitstream is only what it takes for an FPGA to run a different neural network topology.
The CEO took Google’s Tensor Processing Units (TPUs) as an example, which were reworked on a 2nd and a 3rd ASIC spin. Even then, when tasked with different workloads, the TPUs’ efficiency can drop dramatically to only a few percent of its specified peak TeraOps/s figure. What’s more the 3rd TPU version requires water cooling.
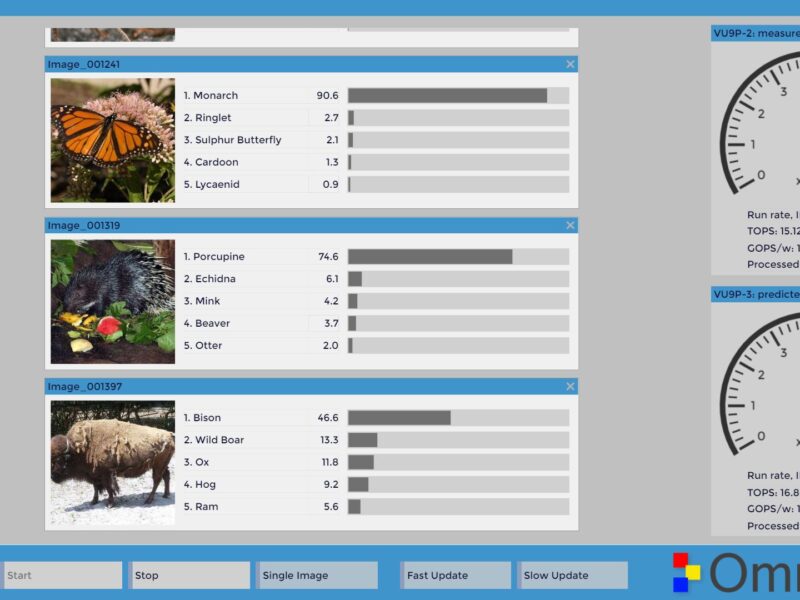
Demonstrated as a GoogLeNet Inception-v1 CNN, using 8-bit integer resolution, the Omnitek DPU achieves 16.8 TOPS performance and is able to inference at over 5,300 images per second on a Xilinx Virtex UltraScale+ XCVU9P-3 FPGA. This makes it highly suited to object detection and video processing applications at the Edge and in the Cloud, such as intelligent super resolution 8K upscaling for which performance is most important.

The maximum number of engines on Omnitek’s DPU was chosen as a perfect match to Xilinx’ Virtex UltraScale+ XCVU9P and its 12,000 MACS and over 6000 DSP slices. Because the engines are all identical and run in parallel, power efficiency is determined by the number of engines put together. Smaller FPGAs could accommodate 4 engines or less.

layout: 12 engines.
Showing a layout of the 12-engine DPU (spreading across 3 dies on the FPGA), Fawcett highlighted some black streaks, noting that the IP actually only requires 23% of logic, the reminder being routing.
According to Fawcett, if the DPU was ported to a less generic FPGA architecture, say an FPGA whose fabric were optimized for neural networks, there would be room for extra processing elements.
“With a dedicated fabric, we could possibly cut out a lot of the die or add more processing elements. FPGA vendors are already paying attention and it seems to be a very sensible conversation to have” Fawcett told eeNews Europe, adding that Xilinx who owns 15% of Omnitek has already given some hints it is working towards that (see Xilinx promises revolutionary architecture at 7nm).
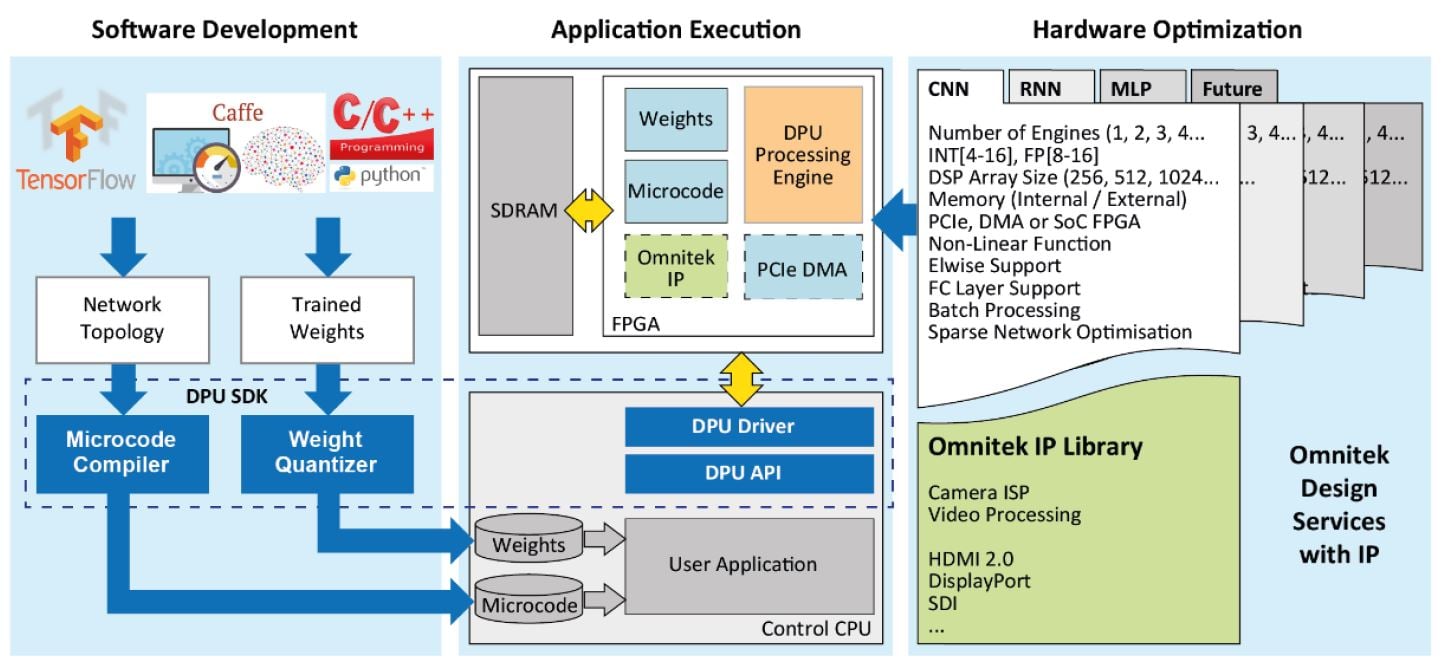
The DPU is fully software programmable in C/C++ or Python using standard frameworks such as TensorFlow. No FPGA design expertise is required, says the company. Omnitek plans to improve the DPU performance even further by sponsoring academic research.
In fact, the company has just announced it is starting a DPhil (PhD) research sponsorship to study novel techniques for implementing deep learning acceleration on FPGAs. It established the Omnitek Oxford University Research Scholarship to fund DPhil students at the Active Vision Laboratory to research novel compute architectures and algorithmic optimisations for machine learning. The work will be performed in collaboration with Omnitek’s own industry-based research to help shape the future of AI compute engines and the algorithms that run on them. This will allow the company to release improved DPU IP for FPGAs to be reprogrammed with.
Omnitek – www.Omnitek.tv/DPU
Related articles:
Xilinx promises revolutionary architecture at 7nm
Silicon chip delivers advanced video image warping and edge blending
Lattice optimizes sensAI stack for always-on, on-device AI
Indo-US startup preps agent-based AI processor
 If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :
If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :



