

AI boost for standard cell layout at 3nm
Nvidia has used reinforcement learning and other types of artificial intelligence to boost the automated layout of its standard cells in advanced process nodes at 5nm and 3nm.
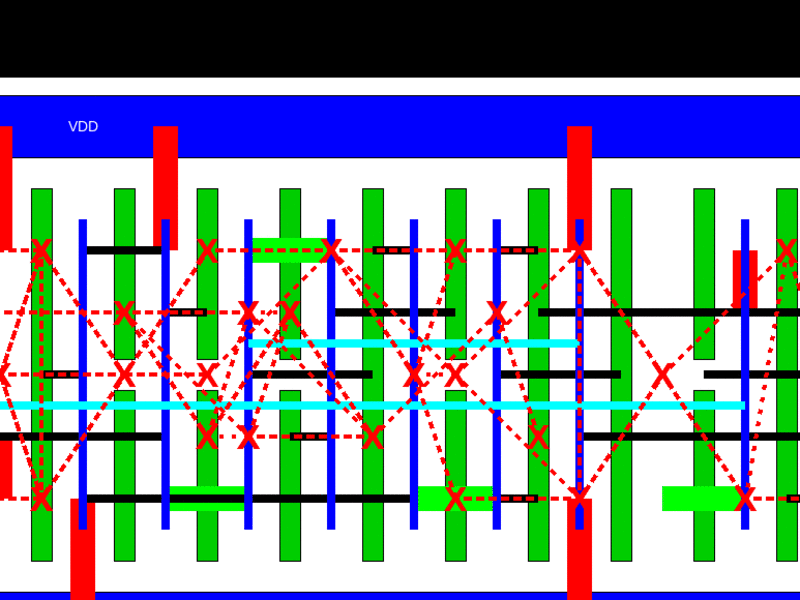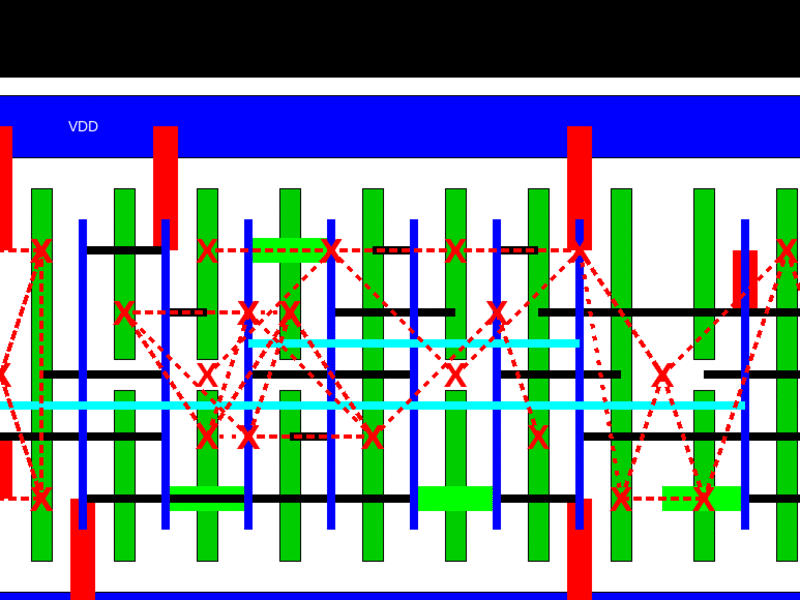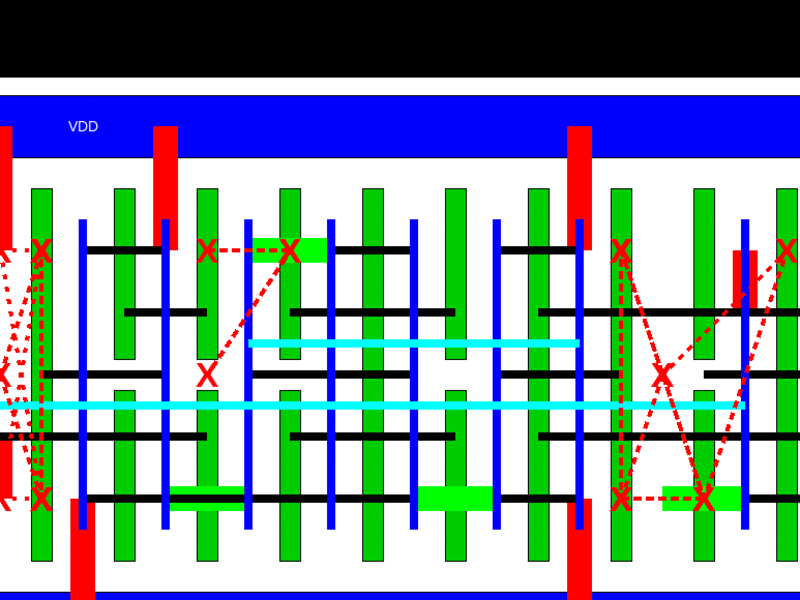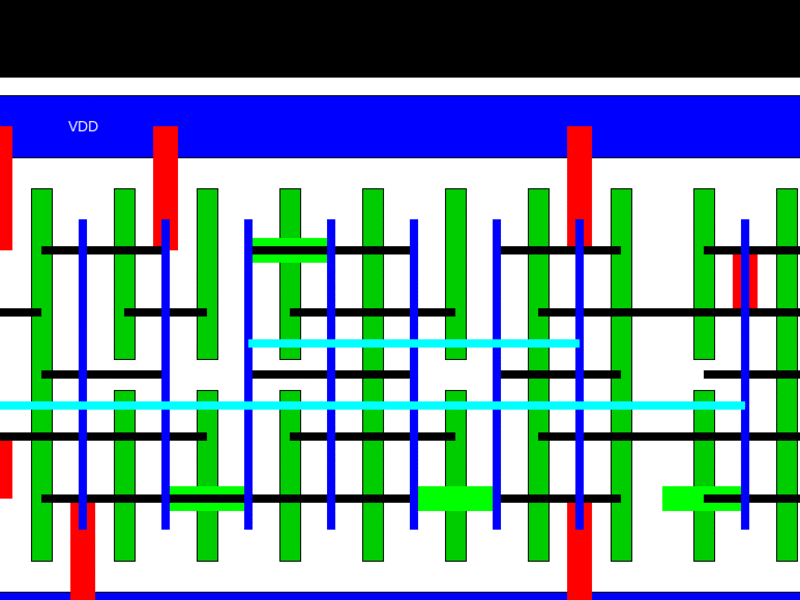
In a pre-print of a paper for the Design Automation Conference in December, the team of Mark Ren, Matt Fojtik and Brucek Khailany developed an automatic standard cell layout generator called NVCell that can generate layouts with equal or smaller area for 92 percent of single row cells in an industry standard cell library on an advanced technology node.
High quality standard cell layout automation in advanced technology nodes is still challenging in the industry today because of complex design rules. The reinforcement learning (RL) is used to address design rule violations during routing and improve the efficiency of the placement of the cells, This leads to smaller die, saving costs and boosting performance.
The researcher used a simulated annealing based algorithm for device placement and pin assignment which performs both device pairing and placement concurrently to find a high quality placement.
Related articles
- Samsung Foundry tapes out 3nm GAA chip
- Apple, Intel are first to adopt TSMC’s 3nm process
- 3nm physical IP tapes out for ARMv9 designs
- Do patents kill innovation? The US patent office is asking
- Europe set to examine Nvidia-ARM deal
- Data centre overtakes gaming at Nvidia
The RL based placement algorithm speeds up the placer that uses simulated annealing. This was able to produce the same quality of layout as the simulated annealing based placer on 84 percent of cells tested after training. This is combined with an RL based method to fix DRC errors given existing routes on standard cells. Trained on one standard cell, the model is transferable to all the standard cells in the Nvidia library
A machine learning based routability predictor helps to predict the routability of a given placement, generating competitive layouts on an additional 9.5 percent of cells.
A genetic algorithm is used for the routing flow to find minimum routes and optimize the DRC errors. Together with the RL based DRC fixer, it found routable DRC-clean cell layouts with reduced widths compared to the best layouts found by expert layout engineers
The beauty is that the more standard cells that are placed, the better the algorithm performs as the model can be further retrained on each cell to improve the results. With millions of standard cells in 5nm and 3nm designs, this will quickly improve the quality of the layout of the chips.
Of course the algorithms are running on Nvidia’s graphic processor units, in this case the training is conducted on a Nvidia V100 GPU.
Related articles
- Microsoft backs Nvidia for AI supercomputer in the cloud
- Standard cell IP library offers 20% silicon area savings
- Siemens buys Dutch IP validation tool developer
- Mentor, ST team on chip process characterisation
Other articles on eeNews Europe
- TI adds network accelerators to boost Sitara microcontrollers
- Segger, ADI team on long reach industrial Ethernet
- Xaar acquires print system integrator for £9m
- Flexible fab could slash chip shortage
- OpenRAN for UK 5G AI smart city deployment
 If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :
If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :




