


CEO interview: 100x power efficiency boost for edge AI processor at Efficient
 Cette publication existe aussi en Français
Cette publication existe aussi en Français
Chip and compiler designer Efficient Computer has demonstrated its highly efficient general purpose edge AI processor architecture.
The code runs on a fabric architecture which is a special data flow optimised for energy efficiency and can run a DSP pipeline at 1.3TOPS/W for edge AI. This is based on a series of 256 tiles as the processing element, each with an ALU and logic to run a single instruction.
“What’s fundamentally different is the architecture was developed with compiler and software stack at the same time from research in Carnegie Mellon and we designed it with generality in mind,” Brandon Lucia, CEO and founder tells eeNews Europe.
The compiler generates a representation of the data flow, places the instructions with an efficient network on chip. A RISC-V core configures the fabric and then shuts down to leave the tiles running, although the fabric can reconfigure itself as a general purpose processor that can run C, C++ or Rust as well as edge AI frameworks and potentially transformer frameworks.
“We don’t need a register flow and we don’t need to instruction fetch every cycle,” said Luca. “A subset of the tiles are also memory access tiles – that’s an efficient way of structuring the memory.”
The company raised $16m back in March for the next phase of the development.
- Efficient Computer raises US$16 million for processor architecture
- Energy-efficient computing needs new devices, architectures says US report
- IBM’s new chip architecture points to faster, more energy-efficient chip
“Our approach spans hardware and software, which is the only path to efficiency. Instead of executing a series of instructions like von Neumann designs, our architecture expresses programs as a “circuit” of instructions that shows which instructions talk to each other. This model lets us lay out the circuit spatially across an array of extremely simple processors and execute the program in parallel, with much simpler hardware (and thus less energy!) than any existing processor,” he said.
“We call this design the Fabric processor architecture, and we have implemented it in the Monza test system on chip (SoC). The Fabric’s compiler was designed alongside the hardware from day one, and it compiles programs written in high-level C or C++.”
The first chip has performance of 1.3 to 1.5TOPS/W which is 500mW to 600mW for the chip. “If you use smaller number of processor elements you have lower power so you can optimise for power for performance through the compiler.”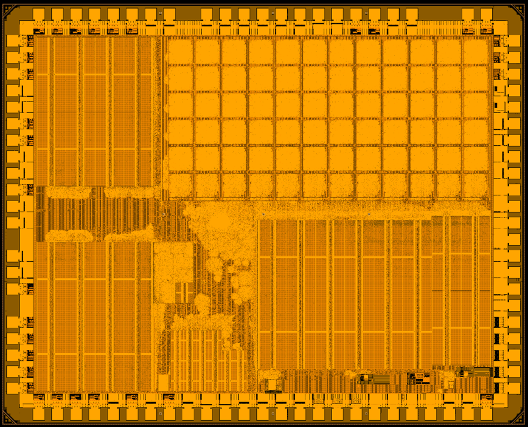
“Today’s computers are horribly inefficient. The dominant “von Neumann” processor design wastes 99% of energy. This inefficiency is, unfortunately, baked deeply into their design. In von Neumann processors, programs are expressed as a sequence of simple instructions, but running programs in a simple sequence is unacceptably slow. Improving performance requires complex hardware to find instructions that can safely run in parallel,” he said.
“Improving efficiency requires a fundamental rethinking of how we design computers. Others have approached this problem by restricting programs, i.e., limiting the processor to only run programs where parallelism is easy to find. These restrictions let designers simplify and specialize the hardware. While this approach improves efficiency, it gives up on general-purpose programmability, which is a huge problem.
“Generality is efficiency: any part of a program that runs inefficiently quickly limits energy-efficiency of the entire system. Moreover, these specialized processors ignore software, which is where the real value lies in computing.
The compiler currently supports TensorFLowLite for machine learning, and support for the ONNX AI framework format is on the roadmap. It is built on the Multi-Level Intermediate Representation (MLIR) developed as part of the LLVM compiler activity to provide flexibility.
“We built the compiler on the MLIR compiler stack so we take the existing TensorFlow flow directly and optimise to the fabric – that’s really powerful as we can take intermediate languages such as Rust and we will support that as well as Python and Matlab,” said Lucia.
“Looking to the future we have a roadmap to scale up the architecture as we are doing design space exploration. Early in 2025 we can hit 100GOPS at 200MHz and we think we can scale that 10 to 100x in performance with the same efficiency.”
Part of this exploration is also looking at transformer frameworks for low power edge AI applications. “If there is a transformer that fits in the memory we can run a transformer, that’s something that is very interesting,” he says.
www.efficient.computer; mlir.llvm.org/
 If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :
If you enjoyed this article, you will like the following ones: don't miss them by subscribing to :





